
✅ この記事の目的
AI秘書シリーズ、ついに今回で 完結 です!
これまで10回にわたって、文字起こし・要約・ToDo・感情スコア・グラフ化…とコツコツ作ってきた分析データたち。
今回はその集大成として、ポータルに載せる「report.json」 を Colab で一気にまとめます!
この1ファイルさえ作れば、「セッションの振り返りが一目でわかる」「コーチと生徒で共有しやすい」
そんな便利な完全レポートが出来上がります。
✅ ゴール
- これまで作ったデータを 1つの辞書に整理
- 音声ファイル名から セッション日付を自動抽出
- Colabで report.json を出力
- あとはポータルにポイッと載せるだけ!
これで、非エンジニアでも「自分専用AI秘書」の基本形が完成です!
ラスト一歩、さくっとやってみましょう 🚀✨
🧩 完成イメージ(report.json)
まずはゴールの形を先にお見せします!
今回作る 「report.json」 は、こんな感じの中身になります👇
{
"session_id": "abc123",
"title": "モチベの波が見えた日",
"date": "2025-06-11",
"summary": "今回のセッションは、冒頭で生徒が最近の英語学習に対する不安を口にしたところから始まりました。中盤では、過去にうまくいった経験を振り返る中で徐々に自信を取り戻し、最後には自発的に次回のアクションを設定するまでに前向きな変化が見られました。全体を通して、感情の波はあるものの、成長と気づきの多い時間となりました。",
"todo": [
"発音練習を毎日5分継続",
"次回までにテキスト5ページ読んでおく"
],
"emotion_score": 4,
"graph_url": "images/graph_abc123.png",
"insight": "セッション前半は自信がやや低下していたが、後半にかけて学びへの意欲が高まった。生徒が自ら次のアクションを提案した点が大きな進歩。",
"speaker_ratio": {
"coach": 40,
"student": 60
},
"speaker_comment": "今回は生徒が多く話すセッションでした。自己開示が進んでおり、コーチは聞き手に回る場面が多かったです。",
"emotion_highlights": [
{ "keyword": "発音練習", "emotion_change": "+2", "note": "できた実感にすごく喜んでいた" },
{ "keyword": "プレゼン準備", "emotion_change": "-3", "note": "焦りと不安を強く感じていた" }
],
"topic_tags": {
"雑談": 6,
"目標確認": 10,
"学習実践": 18,
"振り返り": 12
}
}この中には
- これまでColabで作ってきた 要約・ToDo・感情スコア
- グラフの画像パスや話題タグ
- セッションIDとタイトル
ぜ〜んぶ詰め込んであります!
この形を Colab で自動生成できれば、あとはポータルが自動で読み込んでくれるので、毎回のセッション振り返りが超ラクになりますよ!
📁 必要なファイルと準備物
report.json を作る前に、まずはこれまで作ってきた素材を 手元に揃えておきましょう!
Colabで一気にまとめるときに必要です。
✅ 必要なファイル一覧
| ファイル名 | 役割 |
|---|---|
session_with_speaker.json | 話者情報付きテキスト(第9回で作成) |
session_emotion.json | 感情スコア付きテキスト(第6回で作成) |
session_with_topic.json | 話題タグ付きテキスト(第10回で作成) |
insight.txt | GPTで生成した気づきメモ(第10回で作成) |
graph.png | 感情波グラフ画像(第7回で作成) |
wave_points.csv | 感情の波ポイント(第10回で作成) |
todo.json | セッション中のToDoリスト簡潔版(第4回で作成) |
summary_500chars.txt | セッションの要約(第3回で作成) |
✅ もし途中のファイルがない場合は?
過去回の記事を見直して作り直せます!
👉 まとめリンクは最後に載せるので安心してください!
🔑 1️⃣ セッション情報をまとめる
まずは report.json の土台 になる
「セッションID」や「タイトル」「要約」を Python の辞書にまとめます。
✅ ポイント
- 辞書(dictionary)とは:
「名前と中身をセットで保存する箱」 です!
例えばtitleに「モチベの波が見えた日」などを入れます。 - 後で辞書を JSON 形式に書き出して、ポータルが読み込みます。
- summary は手書きしない!
👉 前回までに作ったsummary_500chars.txtを with open() で読み込んで使います! - 先に
summaryを読み込んでから、辞書を作るとキレイです。
以下のコードでは先に読み込むようになっています。
👇 Colab に貼って実行しておきましょう
# 1️⃣ 要約ファイルを読み込む
with open("summary_500chars.txt", "r", encoding="utf-8-sig") as f:
summary_text = f.read()
# 2️⃣ セッション情報の辞書を作る
session_info = {
"session_id": "abc123",
"title": "モチベの波が見えた日",
"date": "", # 後で自動抽出
"summary": summary_text # ファイルから読み込んだ要約をセット!
}
print(session_info)もしエラーが出るようでしたら、summary_500chars.txtをColaboにアップロードしてみてください。
✅ これを実行しておくと、次のステップで date を自動で追加できます!
💡 補足:
JSONファイルは「メモ帳」などのテキストエディタでも開けます!
見やすくしたい場合は VS Code などのエディタを使うと便利です。
📝 2️⃣ 日付を音声ファイル名から自動抽出する
さきほど作った session_info に、今度は音声ファイル名から 自動で日付を取り出してセット します!
✅ やることの流れ
- 音声ファイル名を Python で変数に入れる
- 正規表現(
re)でyyyy-mm-ddを探す - 見つけたら
session_info["date"]に代入する
✅ なぜ必要?
ファイル名に「2025-06-11」のように日付を含めておくと、セッションがいつ行われたかを自動で拾えて便利だからです。
✅ やり方のポイント
- Python の
re(正規表現)を使って、ファイル名から「yyyy-mm-dd」の形を探すだけ! - 見つけた日付を
session_info["date"]に入れます。
👇 Colab で実行するコード
import re
# 例:ファイル名(今回は)
file_name = "2025-06-11_session_audio.wav"
# 正規表現で yyyy-mm-dd を探す
match = re.search(r"\d{4}-\d{2}-\d{2}", file_name)
if match:
session_info["date"] = match.group()
else:
session_info["date"] = "日付不明"
print(session_info)💡 ポイント
session_infoは 1️⃣ で作ったものを必ず実行済みにしておくことfile_nameは Colab にアップロードした実際のファイル名に合わせて書き換えてください!(例のままだと"2025-06-11_session_audio.wav"が使われます)
💡 重要ポイント
✅ この方法は、ファイル名に「ハイフン区切りの日付(例:2025-06-11)」が含まれていることが前提 です!アンダーバー(2025_06_11)だと自動抽出できないので注意!
👉 もしアンダーバーで保存してる人は、ファイル名を 2025-06-11_session_audio.wav のようにハイフンに直すのがおすすめです。
これで ID・タイトル・要約・日付 が自動でセットされました!
次は 他のデータを全部まとめる ステップに進みます!
🗃️ 3️⃣ 各データを辞書にまとめる
これで session_info にID・タイトル・要約・日付 が揃いました!
次は、これまで作った ToDo・感情スコア・グラフURL・発話比率・insight など、すべてを 辞書に追加 していきます。
✅ やることの流れ
- 必要なファイルを Colab で読み込む
- 読み込んだ内容を
session_infoに追加する - 最後に
print()で確認!
👇 代表コード例(コピペでOK!)
import json
# ✅ ToDoリストを読み込む
with open("todo.json", "r", encoding="utf-8-sig") as f:
todo_list = json.load(f)
# ✅ insight(気づきメモ)を読み込む
with open("insight.txt", "r", encoding="utf-8-sig") as f:
insight_text = f.read()
# ✅ 感情スコア(例:手動または計算済み値)
emotion_score = 4 # 例
# ✅ 発話比率(例:speaker_ratio)
speaker_ratio = {
"coach": 40,
"student": 60
}
# ✅ 話者コメント
speaker_comment = "今回は生徒が多く話すセッションでした..."
# ✅ emotion_highlights(例:手動または wave_points.csv から)
emotion_highlights = [
{"keyword": "発音練習", "emotion_change": "+2", "note": "できた実感にすごく喜んでいた"},
{"keyword": "プレゼン準備", "emotion_change": "-3", "note": "焦りと不安を強く感じていた"}
]
# ✅ topic_tags(例:集計結果)
topic_tags = {
"雑談": 6,
"目標確認": 10,
"学習実践": 18,
"振り返り": 12
}
# ✅ グラフ画像のパス
graph_url = "images/graph_abc123.png" # 例
# ------------------------------------
# session_info に追加していく
# ------------------------------------
session_info["todo"] = todo_list
session_info["emotion_score"] = emotion_score
session_info["graph_url"] = graph_url
session_info["insight"] = insight_text
session_info["speaker_ratio"] = speaker_ratio
session_info["speaker_comment"] = speaker_comment
session_info["emotion_highlights"] = emotion_highlights
session_info["topic_tags"] = topic_tags
# ✅ 最終確認
print(session_info)もしエラーが出るようでしたら、todo.jsonをColaboにアップロードしてみてください。
💡 ポイント
- ファイルは同じフォルダにアップロードしておく
- wave_points.csv は直接読み込むか、必要な箇所だけ手動で抜き出してもOK
- グラフ画像は
imagesフォルダを作ってそこに置くと整理しやすい
これで ポータル用の完全辞書 が出来ました!
次はいよいよ 💾 4️⃣ report.json を保存する へ行きます!
💾 4️⃣ report.json を保存する
これで session_info にポータルに必要な全データ が揃いました!
あとはこれを JSONファイルとして保存 するだけです。
✅ やること
- Python の
jsonモジュールを使う with open()でreport.jsonを作るjson.dump()で書き込む- 保存後にダウンロードする
👇 Colabでそのまま使えるコード
import json
# ✅ report.json を保存する
with open("report.json", "w", encoding="utf-8-sig") as f:
json.dump(session_info, f, ensure_ascii=False, indent=2)
print("✅ report.json を保存しました!")✅ ポイント
ensure_ascii=Falseで日本語も文字化けしない!indent=2で人間が読んでも見やすい!utf-8-sigは Windows ユーザー向けの安心設定!
📥 Colab からPCにダウンロードする
最後にこれをPCに落とすには👇
from google.colab import files
files.download("report.json")これで ポータルに載せる完全レポート (report.json) が完成!
これでシリーズのゴールに到達です 🚀
🎉 完成!これでポータルに載せられる!
ここまでのステップで、セッションの要約・ToDo・感情分析・グラフ・発話比率まで、全部ひとつにまとまった 完成レポート(report.json) が出来上がりました!✨
ポータルに載せる前に、中身をサッと HTML で確認したい場合は、以下のコードを Colab で実行してください👇
import json
from IPython.display import display, HTML
with open("report.json", "r", encoding="utf-8-sig") as f:
report = json.load(f)
html_content = f"""
<h2>Report Preview</h2>
<pre style="background:#f5f5f5; padding:1em; border-radius:8px;">
{json.dumps(report, ensure_ascii=False, indent=2)}
</pre>
"""
display(HTML(html_content))粗削りではありますがブラウザで表示すると以下の様な感じになっています👇
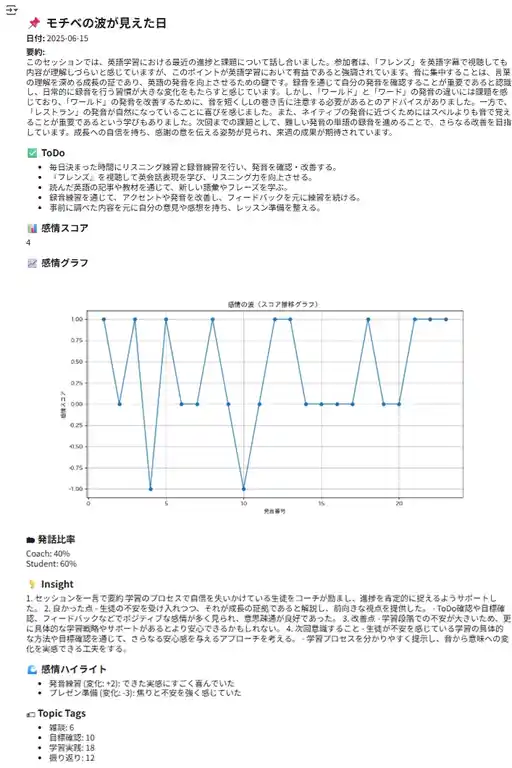
🏁 AI秘書ツール制作シリーズ、これにて完結!
ここまで読んでくれたみなさん、そして一緒に手を動かしてくれたみなさん、本当にお疲れさまでした!
このシリーズでは、「非エンジニアでも、AIとColabを使えばここまで自分だけの秘書が作れる!」ということを、まるっと証明してみせました。
- 文字起こしから始まって
- 要点整理、ToDo、感情分析、グラフ化、
- 発話比率、気づきメモ、そして
- 全部まとめてポータルに載せられる
report.json!
全部、一歩ずつ積み上げてきた成果です。
このツールはまだまだ進化できます。
でも、まずは 「形になる」 を体験できたことが一番の宝物。
これからはこの土台をベースに新しい応用編やアップデートは、単発記事としてゆるっとお届けしていきます。
コードは知らない。でも、作れる。
これからも、誰かの「咲き続ける」をそっと支える相棒として、新しい仕組みを作り続けます。
🌸 I build, You bloom.
AI秘書ツール制作シリーズこれにて完結です!
おつかれさまでした 🚀
🔗 関連リンク|AI秘書ツール制作シリーズ
- 1️⃣ 第1回|文字起こし①:Whisperを動かす準備だけしよう!
- 2️⃣ 第2回|文字起こし②:録音ファイルをポイッと、Whisperで文字起こし!
- 3️⃣ 第3回|要点抽出①:ChatGPTで要点だけ抜き出してみた!
- 4️⃣ 第4回|要点抽出②:抽出結果をToDo形式に整えてみた
- 5️⃣ 第5回|要点抽出③:提出用レポートに仕上げてみよう!
- 6️⃣ 第6回|感情分析①:発言ごとの感情をAIで数値化してみた!
- 7️⃣ 第7回|感情分析②:感情の波をグラフで見える化してみた!
- 8️⃣ 第8回|感情分析③:“気づき”を引き出すレポートをつくろう
- 9️⃣ 第9回|感情分析④:発話のバランスから見えてくること(比率分析編)
- 🔟 第10回|感情分析⑤:感情のゆらぎから“気づき”を拾ってみよう!
- 🏁 【第11回|完結】これが完成形!ポータルに載せる「report.json」をColabで作ろう←(今ここ)
💡 迷ったらこちらも
