
🎯 ChatGPTで「要点だけ!」をスパッと抽出してみた話
こんにちは、SHIRAN.CODERです。
前回までで、Whisperを使って音声を文字に変換し、.txt ファイルとして保存するところまでやってきました。
「とりあえず文字起こしができた!」という状態ですね。おつかれさまです。
で、その文字起こしされたテキスト。
読み返してみて、こう思いませんでしたか?
「うん…読めるけど、どこが大事だったか分かりづらいな」
そうなんです。たとえ短めの音声でも、テキストになると情報量が一気に膨れ上がるんですよね。
それを読み解いて、手作業でまとめ直すのは、なかなか骨が折れる。
✨ということで、今回のテーマはこれ!
ChatGPTに「要点だけ抜き出して!」とお願いしてみよう!
今回のColab作業では、こんな流れで進めていきます👇
- 第2回で保存した
.txtファイルを読み込んで - 発言ごとに ChatGPT に「この発言の要点は?」と質問していく
- 出てきた要点をリスト形式で並べていく
ただの要約じゃありません。
1発言ずつ、ていねいに処理することで、内容のニュアンスや空気感を残しながら、ポイントだけ抽出してもらうというのが今回のミソです。
この3つをChatGPTくんにお願いして、セッションの中身を一気に“整理&要約”できる状態にしていきます。
詳しいアウトプット内容は、このあと改めて確認していきましょう!
📌 今回のゴール
この回の目的は、前回までに文字起こししたテキストを使って、ChatGPTでセッション内容を「整理された形」に変換することです。
いわゆる“会話の中身をスッキリ整える工程”ですね。
具体的には、以下の3つの成果物を得ることをゴールとします👇
✅ 1. 発話ごとの要点リスト
各発言に対して「この発言の要点は?」とGPTに質問し、シンプルで的確な1文まとめを取得します。
コーチング・面談・議事録など、あらゆる対話ログで使える汎用的な形式です。
✅ 2. セッションタイトル(GPT生成)
すべての要点をもとに、セッション全体をひとことで表すタイトルをGPTに考えてもらいます。
例:「発音の壁と向き合った30分」「小さなモヤモヤを整理した日」など。
記録やレポート整理がぐっとラクになります。
✅ 3. セッション全体の要約(300〜500文字)
生成された要点をもとに、全体の流れや話題をコンパクトにまとめた要約文を作成します。
これは次回以降で使う report.json の summary フィールドにも活用する、非常に重要な情報の核になります。
これら3点が揃えば、セッションの内容を「あとから見返しても意味が分かる状態」にできます。
整理・共有・分析のベースがここで完成します。
🧰 作業前に準備しておくもの
ここからは、いよいよChatGPTを使って「要点だけ」を抽出していきます。
その前に、まずは作業に必要なものが揃っているかチェックしておきましょう!
✅ 1. Googleアカウント
Google Colab(コードを動かす環境)を使うために必要です。
Gmailを持っていればOK。ログインしておきましょう。
✅ 2. OpenAIのAPIキー
ChatGPTとColabをつなぐための「鍵」です。
取得がまだの方は、こちらの記事を参考にどうぞ👇
🔗 ChatGPT APIキーの取得方法はこちら
✅ 3. 文字起こし済みのテキストファイル(session_transcript.txt
session_transcript.txt前回(第2回)で文字起こししたデータを、.txt 形式で保存したものを使います。
ファイル名は session_transcript.txt のままでOKです。
準備が整ったら、さっそくColabを立ち上げて、ChatGPTくんに「要点、よろしく!」とお願いしてみましょう💡
🧪 このページの使い方(というか、やり方)
このページは「読むだけ」じゃなく、実際に手を動かして進めていくタイプの実践記事です。
💡 ChatGPTとColabを使った作業を、1ステップずつ、自分でコピーして実行していく流れになります。
「ノートブック配られても、結局なにやってるか分からない…」ってこと、ありますよね。
だから今回は、コードの意味や使い方を、1つずつていねいに解説していきます。
こんな感じで進みます👇
- コードの意味を軽く説明
- コピーしてColabに貼る
- 実行!
- 出てきた結果を一緒に確認
- 次のステップへ!
🔁 この「読んで → コピーして → 実行する」スタイルなら、途中で止まっても自分のペースで再開できます。
「全部渡されてもピンとこない」タイプの人にこそ、おすすめの進め方です◎
🚀 Colab実行ステップ
それでは、いよいよ実行に入っていきましょう💨
まずは、APIキーを設定するところからスタートです!
1ステップずつていねいに進めていくので、安心してついてきてくださいね💡
🔹 Step1:OpenAI APIキーを設定しよう
まず最初に、ChatGPT(OpenAI)と接続するための「鍵」をColabに教えてあげましょう。
その鍵が、あなたのAPIキーです。
🔑 入力する場所(Colabのセル)
以下のコードを、Colabのセルにコピーして貼り付けてください👇
import os
# 🔑 ここに自分のAPIキーを貼り付けてね(""の中だけ書き換える)
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"☝️ 「sk-」で始まる英数字のキーがAPIキーです。
OpenAIのAPIページから取得できます。
🔐 まだAPIキーがない人は?
🌀「そもそもAPIキーってなに?」という方でも、大丈夫!
こちらの解説ページで、取得の流れをわかりやすくまとめています👇
👉 APIキーの取り方ガイド(SHIRAN.CODER)
3分で終わるので、サクッと準備して戻ってきてくださいね◎
🚨 エラー回避のポイント
- APIキーの前後に余計な空白や改行を入れないでください!
例:" sk-xxxx "←こうなるとエラーになります - ダブルクオーテーション
"は消さずに中身だけ差し替えてください - キーを公開しないよう、ブログやSNSには絶対に貼らないでね
これで準備はOK!
次のステップでは、実際に文字起こし済みテキストを読み込んで、GPTくんに渡していきます。
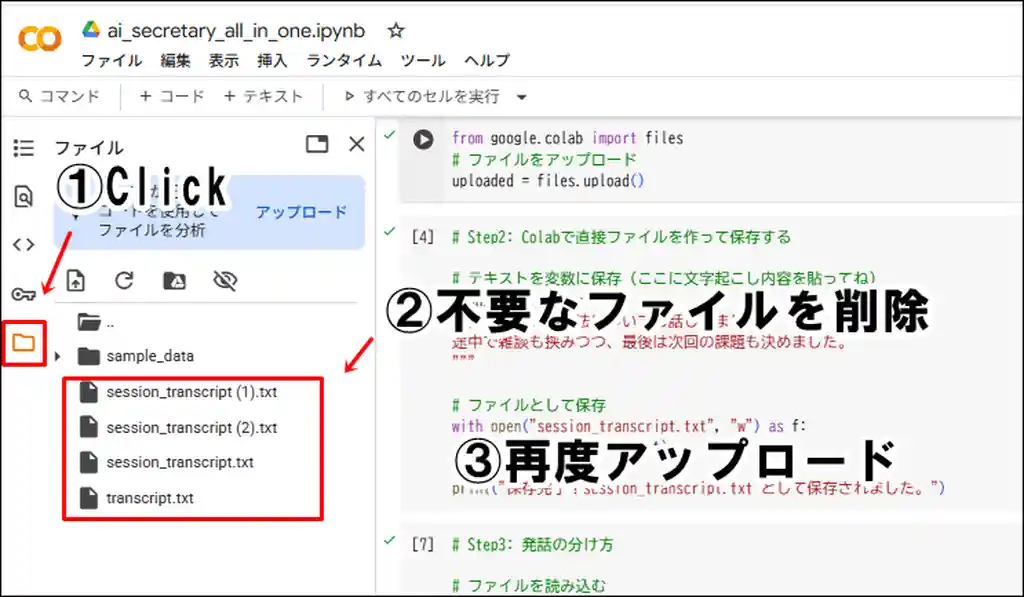
🔹 Step2:第2回で文字起こししたファイルをアップロード
ChatGPTに要点を抽出してもらうには、まずセッションの内容を文字起こししたテキストファイル(.txt)を準備する必要があります。
✅ 方法A:パソコンに保存済みの .txt をアップロードする
アップロードする前に同じファイル名( session_transcript) が無いか確認してください。
ある場合は、再度アップロードする必要はありません。内容が違うものを再度アップロードする場合は古いファイルを消してから再度アップロードしてください。
# パソコンに保存済みの.txt をアップロード
from google.colab import files
# ファイルをアップロード
uploaded = files.upload()🔹 実行すると、ファイル選択画面が出るので、保存してある session_transcript.txt
🔹 アップロードが完了すると、session_transcript.txt
💡 Colabのエラーや操作で困ったら:🔗 Colabトラブル対処&Tipsまとめ
🔹 Step3:セッションテキストを読み込んで発話ごとに準備しよう!
さてさて、ここからいよいよ「要点抽出」に入っていくわけですが、その前に、セッションテキストを発話ごとに整理しておきましょう!
💡 もう安心してください。
Whisperで文字起こし → GPTで整形 という流れを経ているので、テキストの中身はすでに 自然な改行で区切られている はずです。
なので、ここでやることは超シンプル!
テキストを改行ごとに読み込んで、空白を取り除いて、発話リストを作るだけ!
🧩 コード例
以下をそのままコピーして Colab に貼ってください👇
# ✅ GPTで整形済みのテキストを改行単位で読み込む(エンコーディング指定)
with open("session_transcript.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
segments = [line.strip() for line in lines if line.strip()]
print(f"{len(segments)} 発話に分割されました!")
print(segments[:5])🔑 これで準備バッチリ!
これで、セッションテキストが発話ごとにキレイに整列しました。
あとはこの segments を、GPTくんにポイポイ投げて「要点教えて!」とお願いするだけです✨
🔹 Step4:GPTで1発言ずつ要点抽出してみよう
さあいよいよ本番。
ここからは、1つずつ分けた発話をChatGPTにポイポイ投げて、要点だけを抜き出してもらうステップです!
🧠 「要点だけ教えて」って、どうやってGPTに伝えるの?
実はこれ、コードの中で直接「この発言の要点を教えて!」と書いているわけではありません。
えっ⁉と思いますよね。でもちゃんと理由があります。
ChatGPTにやってほしいことは、「キャラ設定(=指示)」として事前に伝えておくのが基本なんです。
この役割を担うのが system ロールです。
📌 systemロールとは?
- GPTに「あなたはこういう人です」とあらかじめ指示を出す部分。
- たとえば「あなたは優秀な会議議事録ライターです」など。
{"role": "system", "content": "あなたは優秀な議事録ライターです。発言から要点だけを抜き出してください。"}この1文を見てGPTくんはこう思います
「OK、今日は“議事録ライター”モードで、要点だけ抜き出せばいいんだな!」
💬 userロールとは?
- 実際にGPTに渡すテキスト(=文字起こし1発言ぶん)を渡すところ。
- ここではただの文字起こしテキストだけを渡します。
{"role": "user", "content": "最近ちょっと英語に対するやる気がなくて…"}ここに「要点を教えて」って書いてなくても、GPTは“議事録ライター”としての自分の仕事を理解しているので、ちゃんと要点を返してくれるんです。えらい!
🧪 実際に動かしてみよう!
以下のコードで、セリフを1つずつGPTに渡して、要点を抽出してもらいます👇
(APIキーはすでに設定済みの前提)
from openai import OpenAI
import json
from google.colab import files
# ✅ クライアントを作る
client = OpenAI()
# GPTを呼び出す関数
def extract_summary(text):
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "あなたは優秀な議事録ライターです。各発言から要点をひとことで抜き出してください。"
},
{"role": "user", "content": text}
]
)
return response.choices[0].message.content
# ✅ 要点抽出を実行
results = []
for segment in segments:
summary = extract_summary(segment)
results.append({
"発言": segment,
"要点": summary
})
print("🔹 発言:", segment)
print("📝 要点:", summary)
print("-" * 40)
# ✅ JSON に保存
with open("/content/summary_list.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print("✅ 要点リストを summary_list.json に保存しました!")
# ✅ ダウンロード
files.download("/content/summary_list.json")🔍 text とは?
text というのは、ループで GPT に渡される 各セリフ(発言内容) のことです。
system で「こうしてね」と役割を決めておけば、user には発言の中身だけをポンッと渡すだけで OK!
💾 抽出結果を確認しながら、そのまままとめて保存!
今回のコードでは、抽出した要点をその場で画面に表示しつつ、まとめて results に追加して、ループが終わったらすぐ JSON に保存 する形にしています。
このJSONファイルは次回使うのでデスクトップに出しておくと分かりやすいです。
🔹 Step5:出力された要点リストを確認しよう
これまでのステップで、ChatGPTくんが1発言ずつ要点を返してくれる状態が整いました。
ここでは、それらをまとめてリストに保存しておいて、あとで一気に見返せるようにしておきましょう!
🧩 まずはリアルタイムで確認しよう
まずは、GPTが返してくれた要点をprint() で1つずつ画面に表示して、「ちゃんと要点取れてるな〜」を目で確認してみます。
# 要点をためておくリストを用意
results = []
# 全発話に対して要点抽出を実行
for i, seg in enumerate(segments):
summary = extract_summary(seg)
print(f"🔹 発言{i+1}: {seg}")
print(f"📝 要点: {summary}")
print("-" * 50)
results.append({"発言": seg, "要点": summary})🖨️ print() ってなに?
Pythonでは、print() を使うと結果を画面に表示できます。
これを入れないと、ChatGPTが返した要点が見えないので、途中経過を確認するときは必須です!
✅ これで何が手に入るの?
このコードを実行すると、
- 発言内容
- それに対応する要点
がペアでズラッと表示されます。
さらに、results というリストに全ペアが自動で保存されるので、あとでファイルに書き出したり、レポートに組み込むのも楽チンです✨
✨ ちょっとだけ試したいときは?
「発話が多いから、いきなり全部やるのは心配…」という人は、まずは最初の10個だけ試す方法がおすすめです!
やり方はカンタン👇
for i, seg in enumerate(segments):の部分を
for i, seg in enumerate(segments[:10]):に書き換えてください。
📝 segments[:10] は、「segments の最初の10個だけ使ってね」という意味です!
Pythonではこうやって「一部分だけ取り出す」ことをスライスと呼びます。
✅ まとめ
print()で要点がちゃんと取れているか確認しよう!resultsに全部たまっているので、あとでファイル保存も楽チン。- まずは少ない数でテスト → OKなら全部処理するのがおすすめ!
🔹 Step6:タイトルとセッション要約を作って保存しよう
これまでで、発話ごとの要点リストが results にバッチリたまりました!
次はこの要点を使って、ChatGPTくんに
- セッション全体を一言で表す「タイトル」
- セッション全体の流れがパッとわかる「300〜500文字の要約」
を考えてもらいましょう!
🧩 なんでタイトルと要約が必要なの?
- タイトル:あとで検索・整理するときに超便利。記録を見返すときに「どの話だったっけ?」が一発でわかる!
- 300〜500文字の要約:レポートや
report.jsonにそのまま使える“振り返り文”。生徒さんや自分用メモとしても超役立ちます◎
📝 具体的なコード例
以下のコードをそのまま Colab に貼って実行してください👇
1️⃣ まずは、要点を全部つなげて「まとめテキスト」を作る
# results から要点だけを取り出して、改行でつなげます
# 例:要点1 → 改行 → 要点2 → 改行 → ... という形にまとめます
all_summaries = "\n".join([item["要点"] for item in results])
# ちゃんと作れたか確認:最初の500文字だけ表示してみます
print("🔍 まとめテキスト(最初の500文字):\n")
print(all_summaries[:500])2️⃣ GPTに「タイトル」を考えてもらう
# タイトルを作ってもらうためのお願い(プロンプト)を作ります
title_prompt = f"""
以下はセッションの要点一覧です。
この内容を一言で表す「セッションタイトル」を1つだけ考えてください。
{all_summaries}
"""
# GPTにお願いしてタイトルを生成します
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは要約のプロです。"},
{"role": "user", "content": title_prompt}
]
)
# 生成されたタイトルを変数に入れておきます
title = response.choices[0].message.content
print("🎯 セッションタイトル:", title)3️⃣ GPTに300〜500文字の要約を作ってもらう
# 要約を作ってもらうプロンプト
summary_prompt = f"""
以下はセッションの要点一覧です。
この内容をもとに、話の流れがわかるように300〜500文字程度で要約してください。
{all_summaries}
"""
# GPTにお願いして要約を生成します
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは優秀な要約ライターです。"},
{"role": "user", "content": summary_prompt}
]
)
# 生成された要約を変数に入れておきます
session_summary = response.choices[0].message.content
print("\n🗒 セッション要約(300〜500文字):\n")
print(session_summary)4️⃣ ファイルに保存して、パソコンにダウンロードする
# タイトルをファイルに保存
with open("/content/summary_title.txt", "w") as f:
f.write(title)
# 要約をファイルに保存
with open("/content/summary_500chars.txt", "w") as f:
f.write(session_summary)
# PCにダウンロードする
from google.colab import files
files.download("/content/summary_title.txt")
files.download("/content/summary_500chars.txt")✅ これで準備完了!
title→ セッションタイトルsession_summary→ 300〜500文字の全体要約
として パソコンに保存 できます!
次回(ToDo化編)では summary_list.json と一緒に使うので、必ず保存しておきましょう✨
🔚 まとめと次回予告
おつかれさまでした!
ここまでで、セッションの文字起こしデータから…
- 発話ごとの要点リスト
- セッションを一言で表すタイトル
- 全体の流れがパッとわかる300〜500文字の要約
を、すべて ChatGPTにおまかせして抽出できる状態 になりました 🎉
これさえあれば、毎回のセッションを
- 「どこがポイントだったっけ?」
- 「この回のテーマって何だった?」
と迷子にならずに整理できます。
コーチングでも会議メモでも、人間の脳みその負担をかなり軽くできるので、どんどん使い倒してください◎
🗂 次回の内容
次回はいよいよ、今回作った 要点リスト+ToDo+要約 をもとに、
- 提出用のレポートとして綺麗に整形
- ファイルに保存して共有できる形にする
- さらに
report.jsonにも組み込める準備をする
という仕上げ作業に入ります!
ここまで来れば、AI秘書ツールの基盤がほぼ完成です😁
ではまた次回!
今日の自分を褒めつつ、AIくんにも「おつかれ!」って言ってあげてください 🫶
🔗 関連リンク|AI秘書ツール制作シリーズ
- 1️⃣ 第1回|文字起こし①:Whisperを動かす準備だけしよう!
- 2️⃣ 第2回|文字起こし②:録音ファイルをポイッと、Whisperで文字起こし!
- 3️⃣ 第3回|要点抽出①:ChatGPTで要点だけ抜き出してみた!←(今ここ)
- 4️⃣ 第4回|要点抽出②:抽出結果をToDo形式に整えてみた
- 5️⃣ 第5回|要点抽出③:提出用レポートに仕上げてみよう!
- 6️⃣ 第6回|感情分析①:発言ごとの感情をAIで数値化してみた!
- 7️⃣ 第7回|感情分析②:感情の波をグラフで見える化してみた!
- 8️⃣ 第8回|感情分析③:“気づき”を引き出すレポートをつくろう
- 9️⃣ 第9回|感情分析④:発話のバランスから見えてくること(比率分析編)
- 🔟 第10回|感情分析⑤:感情のゆらぎから“気づき”を拾ってみよう!
- 🏁 【第11回|完結】これが完成形!ポータルに載せる「report.json」をColabで作ろう
💡 迷ったらこちらも
